Meta Unveils Open Source Llama 3.2: AI That Sees And Fits in Your Pocket
1 year ago admin
It’s been a good week for open-source AI.
On Wednesday, Meta announced an upgrade to its state-of-the-art large language model, Llama 3.2, and it doesn’t just talk—it sees.
More intriguing, some versions can squeeze into your smartphone without losing quality, which means you could potentially have private local AI interactions, apps and customizations without sending your data to third party servers.
Unveiled Wednesday during Meta Connect, Llama 3.2 comes in four flavors, each packing a different punch. The heavyweight contenders—11B and 90B parameter models—flex their muscles with both text and image processing capabilities.

They can tackle complex tasks such as analyzing charts, captioning images, and even pinpointing objects in pictures based on natural language descriptions.
Llama 3.2 arrived the same week as Allen Institute’s Molmo, which claimed to be the best open-source multimodal vision LLM in synthetic benchmarks, performing in our tests on par with GPT-4o, Claude 3.5 Sonnet, and Reka Core.
Zuckerberg’s company also introduced two new flyweight champions: a pair of 1B and 3B parameter models designed for efficiency, speed, and limited but repetitive tasks that don’t require too much computation.
These small models are multilingual text maestros with a knack for “tool-calling,” meaning they can integrate better with programming tools. Despite their diminutive size, they boast an impressive 128K token context window—the same as GPT4o and other powerful models—making them ideal for on-device summarization, instruction following, and rewriting tasks.
Meta’s engineering team pulled off some serious digital gymnastics to make this happen. First, they used structured pruning to trim the unnecessary data from larger models, then employed knowledge distillation—transferring knowledge from large models to smaller ones—to squeeze in extra smarts.
The result was a set of compact models that outperformed rival competitors in their weight class, besting models including Google’s Gemma 2 2.6B and Microsoft’s Phi-2 2.7B on various benchmarks.
Meta is also working hard to boost on-device AI. They’ve forged alliances with hardware titans Qualcomm, MediaTek, and Arm to ensure Llama 3.2 plays nice with mobile chips from day one. Cloud computing giants aren’t left out either—AWS, Google Cloud, Microsoft Azure, and a host of others are offering instant access to the new models on their platforms.
Under the hood, Llama 3.2’s vision capabilities come from clever architectural tweaking. Meta’s engineers baked in adapter weights onto the existing language model, creating a bridge between pre-trained image encoders and the text-processing core.
In other words, the model’s vision capabilities don’t come at the expense of its text processing competence, so users can expect similar or better text results when compared to Llama 3.1.
The Llama 3.2 release is Open Source—at least by Meta’s standards. Meta is making the models available for download on Llama.com and Hugging Face, as well as through their extensive partner ecosystem.
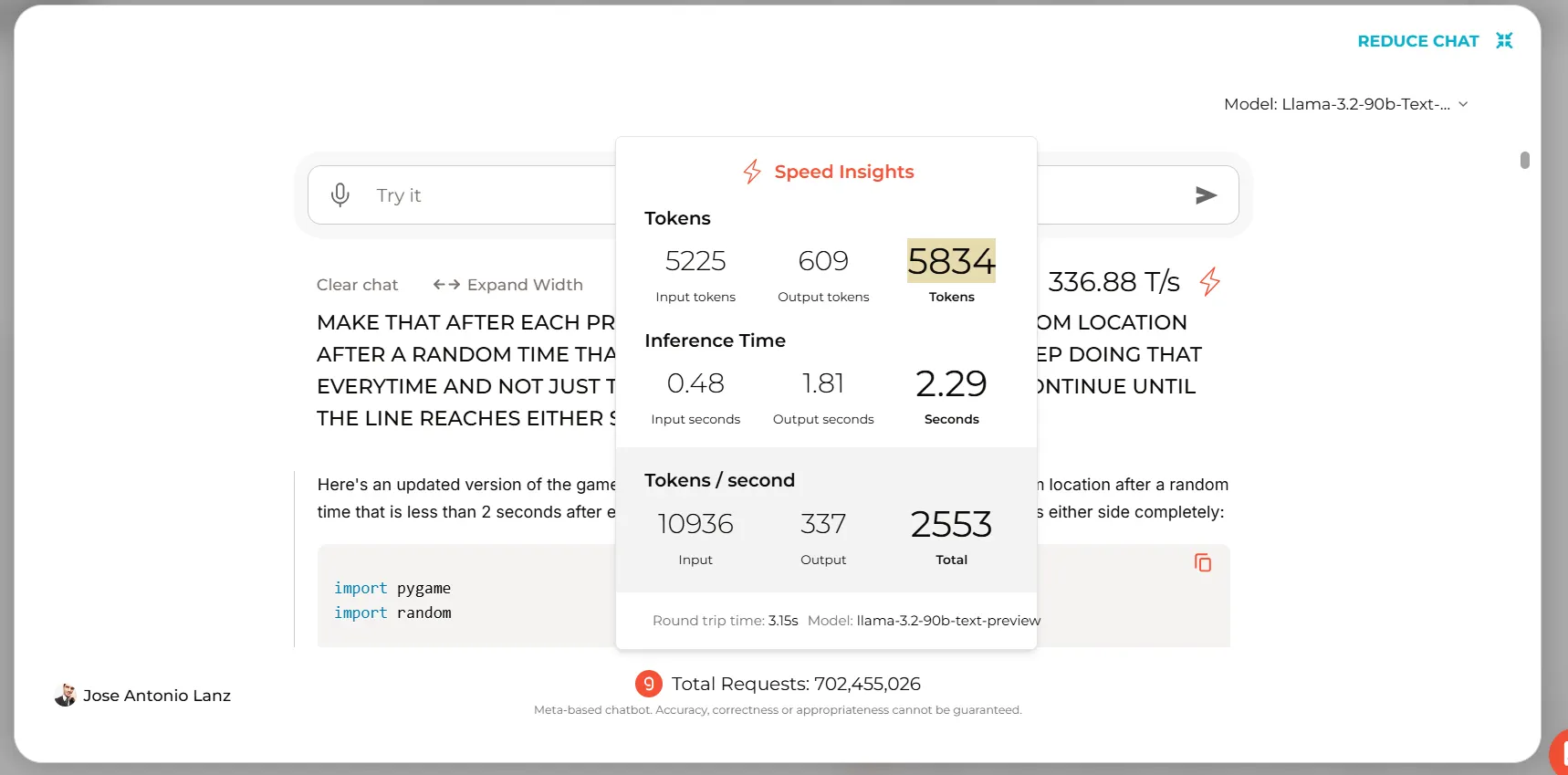
Those interested in running it on the cloud can use their own Google Collab Notebook or use Groq for text-based interactions, generating nearly 5000 tokens in less than 3 seconds.
Riding the Llama
We put Llama 3.2 through its paces, quickly testing its capabilities across various tasks.
In text-based interactions, the model performs on par with its predecessors. However, its coding abilities yielded mixed results.
When tested on Groq’s platform, Llama 3.2 successfully generated code for popular games and simple programs. Yet, the smaller 70B model stumbled when asked to create functional code for a custom game we devised. The more powerful 90B, however, was a lot more efficient and generated a functional game on the first try.
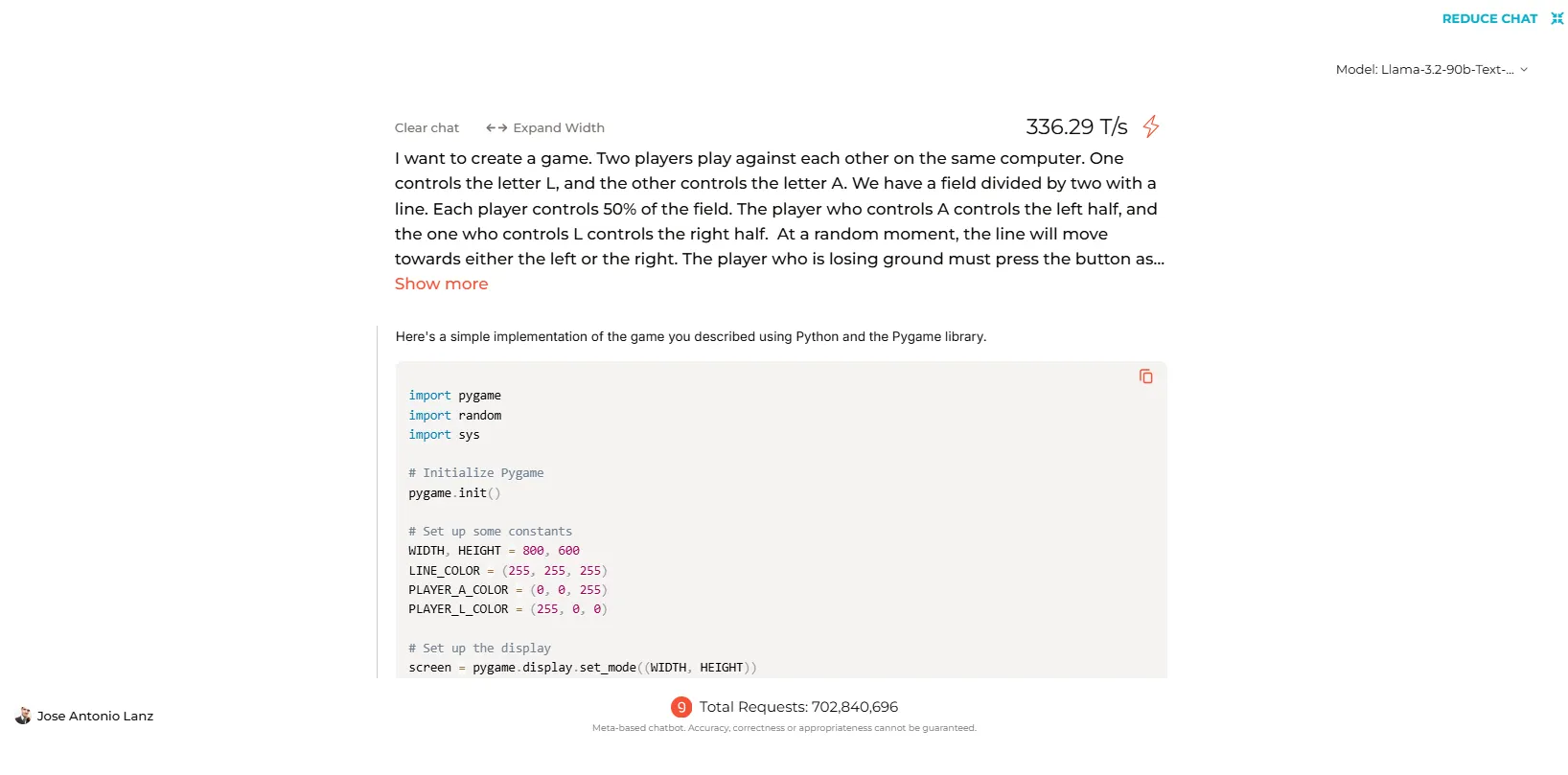
You can see the full code generated by Llama-3.2 and all the other models we tested by clicking on this link.
Identifying styles and subjective elements in images
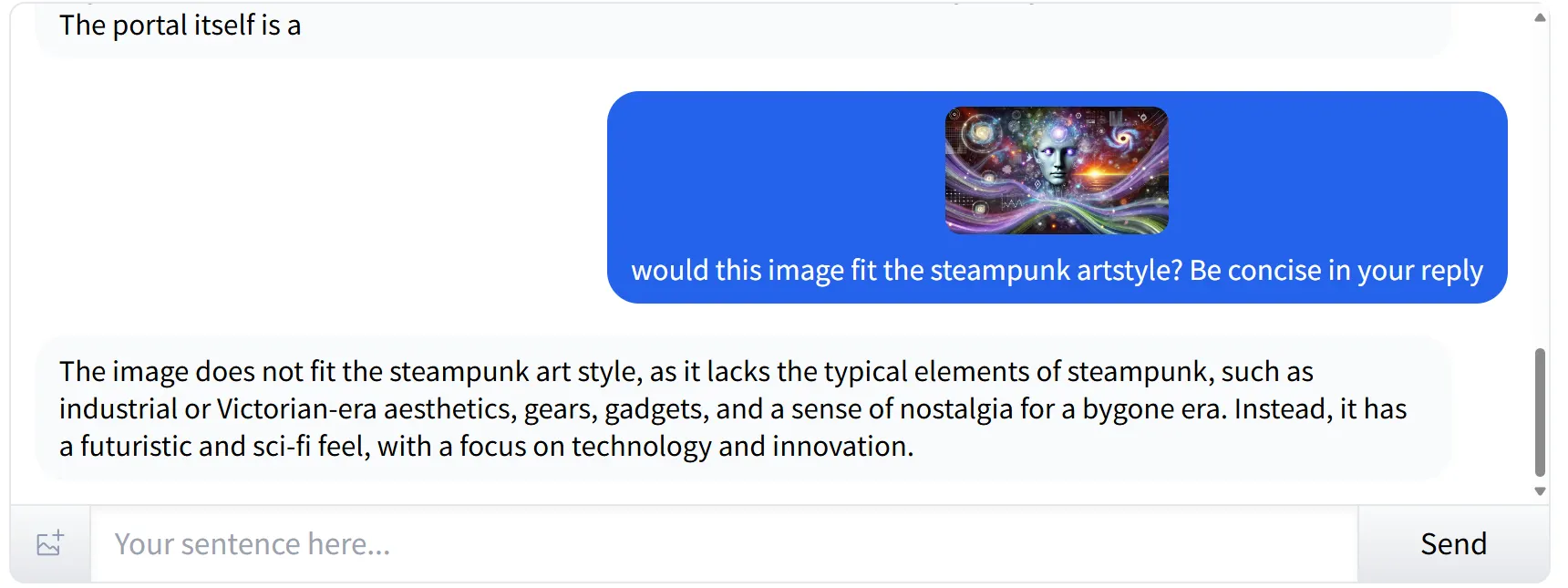
Llama 3.2 excels at identifying subjective elements in images. When presented with a futuristic, cyberpunk-style image and asked if it fit the steampunk aesthetic, the model accurately identified the style and its elements. It provided a satisfactory explanation, noting that the image didn’t align with steampunk due to the absence of key elements associated with that genre.
Chart Analysis (and SD image recognition)

Chart analysis is another strong suit for Llama 3.2, though it does require high-resolution images for optimal performance. When we input a screenshot containing a chart—one that other models like Molmo or Reka could interpret—Llama’s vision capabilities faltered. The model apologized, explaining that it couldn’t read the letters properly due to the image quality.
Text in Image Identification
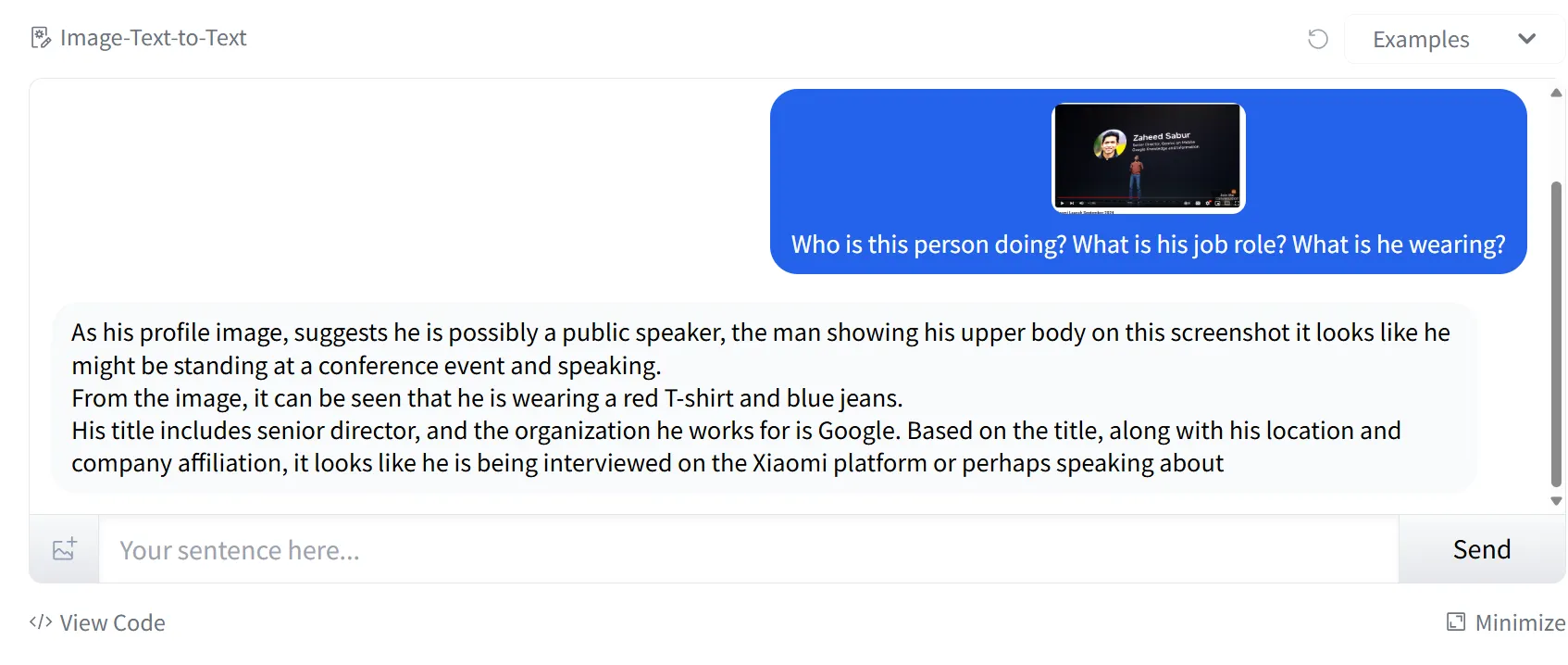
While Llama 3.2 struggled with small text in our chart, it performed flawlessly when reading text in larger images. We showed it a presentation slide introducing a person, and the model successfully understood the context, distinguishing between the name and job role without any errors.
Verdict
Overall, Llama 3.2 is a big improvement over its previous generation and is a great addition to the open-source AI industry. Its strengths are in image interpretation and large-text recognition, with some areas for potential improvement, particularly in processing lower-quality images and tackling complex, custom coding tasks.
The promise of on-device compatibility is also good for the future of private and local AI tasks and is a great counterweight to close offers like Gemini Nano and Apple’s proprietary models.
Edited by Josh Quittner and Sebastian Sinclair
Generally Intelligent Newsletter
A weekly AI journey narrated by Gen, a generative AI model.